It’s Memorial Day and my dissertation defense is tomorrow. This week I’m phoning in my blog.
I had the opportunity to teach a short course last week that was part of a larger workshop focused on ecosystem restoration. A fellow grad student and I taught a session on Excel and R for basic data analysis. I insisted on teaching the R portion given my intense hatred for Excel. I wanted to share the slides I presented for the workshop since most of my blogs haven’t been very helpful for beginners. Consider this material my contribution to the already expansive collection of online resources for learning R.
Our short course provided a background to basic data analysis, an introduction using Excel, and an introduction using R. We used a simulated dataset to evaluate the success of a hypothetical ecosystem restoration (produced by my colleague, S. Berg). The dataset provided information on the abundance of redwing blackbirds at a restored plot and a reference plot at each of three sites over a six year period. Our analyses focused on comparing mean abundances between restoration and reference sites (t-tests) and an evaluation of abundance over time (regression). The stats are understandably basic but they should be useful for beginning R users.
The first presentation was a general introduction to R (my hopeless attempt to get people excited) and the second was an introduction to R for data analysis. I’ve uploaded the dataset if anyone is interested trying the analyses on their own. I’ve also included my LaTeX code for the true geeks.
Enjoy!

\documentclass[xcolor=svgnames]{beamer}
%\documentclass[xcolor=svgnames,handout]{beamer}
\usetheme{Boadilla}
\usecolortheme[named=ForestGreen]{structure}
\usepackage{graphicx}
\usepackage[final]{animate}
%\usepackage[colorlinks=true,urlcolor=blue,citecolor=blue,linkcolor=blue]{hyperref}
\usepackage{breqn}
\usepackage{xcolor}
\usepackage{booktabs}
\usepackage{tikz}
\usetikzlibrary{shadows}
\usepackage[noae]{Sweave}
\definecolor{links}{HTML}{2A1B81}
\hypersetup{colorlinks,linkcolor=links,urlcolor=links}
\usepackage{pgfpages}
%\pgfpagesuselayout{4 on 1}[letterpaper, border shrink = 5mm, landscape]
\begin{document}
\SweaveOpts{concordance=TRUE}
\title[Intro to R]{Introduction to \includegraphics[width=0.07\textwidth]{Rlogo.jpg}}
\author[M. Beck and S. Berg]{Marcus W. Beck \and Sergey Berg}
\institute[UofM]{Department of Fisheries, Wildlife, and Conservation Biology \\ University of Minnesota, Twin Cities}
\date{May 21, 2013}
\titlegraphic{
\centerline{
\begin{tikzpicture}
\node[drop shadow={shadow xshift=0ex,shadow yshift=0ex},fill=white,draw] at (0,0) {\includegraphics[width=0.6\textwidth]{peeper.jpg}};
\end{tikzpicture}}
}
%%%%%%
\begin{frame}
\vspace{-0.3in}
\titlepage
\end{frame}
%%%%%%
\begin{frame}{What you'll learn about \hspace{0.2em}\includegraphics[width=0.07\textwidth]{Rlogo.jpg}}
\setbeamercovered{again covered={\opaqueness<1->{25}}}
\onslide<1->
\begin{itemize}
\itemsep12pt
\item What is R?
\item What's possible with R?
\begin{itemize}
\item CRAN and packages
\end{itemize}
\item R basics
\begin{itemize}
\item Installation
\item Command-line interface
\item Coding basics
\item Functions and objects
\item Data import and manipulation
\end{itemize}
\item Help!\\~\\
\end{itemize}
\pause
\Large
\centerline{\emph{Interactive!}}
\end{frame}
\section{Background}
%%%%%%
\begin{frame}{What is \includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.2em}? }
\setbeamercovered{again covered={\opaqueness<1->{25}}}
\onslide<1->
R is a language and environment for statistical computing and graphics
[\href{http://www.r-project.org/}{r-project.org}]\\~\\
\onslide<2->
R is a computer language that allows the user to program algorithms and use tools that
have been programmed by others [Zuur et al. 2009]\\~\\
\onslide<3->
Different from other statistics software because it is also a programming language...
\end{frame}
%%%%%%
\begin{frame}{What is \includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.2em}? }
\begin{center}
\begin{tikzpicture}
\begin{scope}
% The transparency:
\begin{scope}[fill opacity=0.5]
\fill[blue] (-2,0) circle (2.5);
\fill[green] (2,0) circle (2.5);
\end{scope}
% letterings and missing pieces:
\draw[align=center] (-2,0) circle (2.5) node[scale=1.2] {Programming};
\draw[align=center] (2,0) circle (2.5) node[scale=1.2] {Statistics};
\draw (0,0) node[scale=2] {R};
\end{scope}
\end{tikzpicture}\\~\\
R is both... this creates a steep learning curve.
\end{center}
\end{frame}
%%%%%%
\begin{frame}[t]{What is \includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.2em}? }
\vspace{-0.1in}
\begin{columns}
\begin{column}{0.4\textwidth}
R is becoming the statistical software of choice\\~\\
Plot of Google scholar hits over time for different software packages
[\href{http://r4stats.com/articles/popularity/}{r4stats.com}]
\end{column}
\begin{column}{0.5\textwidth}
\begin{center}
\includegraphics[width=1.1\textwidth]{r_google.png}
\end{center}
\end{column}
\end{columns}
\end{frame}
%%%%%%
\begin{frame}[t]{What is \includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.2em}? }
\vspace{-0.1in}
\begin{columns}
\begin{column}{0.4\textwidth}
R is becoming the statistical software of choice\\~\\
Exponential growth in number of contributed packages
[\href{http://r4stats.com/articles/popularity/}{r4stats.com}]
\end{column}
\begin{column}{0.5\textwidth}
\begin{center}
\includegraphics[width=1.1\textwidth]{r_package.png}
\end{center}
\end{column}
\end{columns}
\end{frame}
%%%%%%
\begin{frame}{What's possible with \includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.2em}? }
R is incredibly flexible, if you want something done, someone else has written the code...\\~\\
\onslide<2->
R is open-source software, which mean it's free and is supported by a large network of contributors - the Comprehensive R Network [\href{http://cran.us.r-project.org/}{CRAN}]\\~\\
\onslide<3->
CRAN is a collection of sites which carry identical material, consisting of the R distribution(s), the contributed extensions, documentation for R, and binaries [\href{http://cran.us.r-project.org/faqs.html}{R FAQ}]\\~\\
\onslide<4->
Basically a repository of R utilities that others have written \onslide<5->- the \href{http://cran.r-project.org/web/views/}{CRAN task views} contain descriptions of contributed packages by category
\end{frame}
%%%%%%
\begin{frame}[t]{What's possible with \includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.2em}? }
\begin{center}
\includegraphics{cran_view1.png}
\end{center}
\end{frame}
%%%%%%
\begin{frame}[t]{What's possible with \includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.2em}? }
\begin{center}
\includegraphics{cran_view2.png}
\end{center}
\end{frame}
%%%%%%
\begin{frame}[t,fragile]{What's possible with \includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.2em}? }
R has a base package that is included in installation, others are downloaded as needed\\~\\
<<echo=true,eval=false>>=
install.packages('newpackage')
@
\vspace{0.2in}
The base package will be sufficient for most of your needs - includes arithmetic, input/output, basic programming support, graphics, etc.\\~\\
Contributed packages will meet your other needs - now exceed 4000
\end{frame}
%%%%%%
\begin{frame}[t,fragile]{What's possible with \includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.2em}? }
<<eval=false,echo=true>>=
demo(package = .packages(all.available = TRUE))
@
List of demonstrations with available packages - examples from ggplot2 package
\begin{columns}
\begin{column}{0.5\textwidth}
\begin{center}
\includegraphics[width=\textwidth]{ggplot1.png}
\end{center}
\end{column}
\begin{column}{0.5\textwidth}
\begin{center}
\includegraphics[width=\textwidth]{ggplot3.png}
\end{center}
\end{column}
\end{columns}
\end{frame}
%%%%%%
\begin{frame}[t,fragile]{What's possible with \includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.2em}? }
<<eval=false,echo=true>>=
demo(package = .packages(all.available = TRUE))
@
List of demonstrations with available packages - examples from ggplot2 package
\begin{columns}
\begin{column}{0.5\textwidth}
\begin{center}
\includegraphics[width=\textwidth]{ggplot2.png}
\end{center}
\end{column}
\begin{column}{0.5\textwidth}
\begin{center}
\includegraphics[width=\textwidth]{ggplot4.png}
\end{center}
\end{column}
\end{columns}
\end{frame}
\section{Basics}
%%%%%%
\begin{frame}[t]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.01in} basics}
Installation - visit \href{http://cran.us.r-project.org/}{r-project.org} and follow directions
\centerline{\includegraphics{download.png}}
\end{frame}
%%%%%%
\begin{frame}[t]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.01in} basics}
Or visit \href{http://pbil.univ-lyon1.fr/Rweb/}{Rweb} for an online version (not recommended)
\centerline{\includegraphics{rweb.png}}
\end{frame}
%%%%%%
\begin{frame}[t]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.01in} basics}
A text editor is highly recommended, e.g. \href{http://www.rstudio.com/}{RStudio}\\~\\
\centerline{\includegraphics[width=0.65\textwidth]{Rstudio.png}}
\end{frame}
%%%%%%
\begin{frame}[t]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.01in} basics}
How is R different from Excel? \onslide<2-> R is a command-line interface\\~\\
\centerline{\includegraphics[width=0.7\textwidth]{command_line.png}}
\onslide<3>
\centerline{\emph{What next??}}
\end{frame}
%%%%%%
\begin{frame}[fragile]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.01in} basics}
Lines of code are executed by R at the prompt (\textit{\texttt{>}})\\~\\
\onslide<2>
Enter the code and press enter, the output is returned\\~\\
<<echo=T,results=tex>>=
print('hello world!')
2+2
(2+2)/4
rep("a",4)
@
\end{frame}
%%%%%%
\begin{frame}[fragile]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.01in} basics}
A disadvantage of code is that everything entered must be 100 \% correct
\begin{Schunk}
\begin{Sinput}
> 2+2a
\end{Sinput}
\begin{Soutput}
Error: unexpected symbol in "2+2a"
\end{Soutput}
\begin{Sinput}
> a
\end{Sinput}
\begin{Soutput}
Error: object 'a' not found
\end{Soutput}
\end{Schunk}
\onslide<2>
\vspace{0.2in}
But this enables a complete documentation of your workflow... \\~\\
...your code is a living document of your analyses.
\end{frame}
%%%%%%
\begin{frame}[t,fragile]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.01in} basics}
Assigning data to R objects is critical for analysis\\~\\
\onslide<2>
Assignment is possible using \textit{\texttt{<-}} or \textit{\texttt{=}}\\~\\
<<eval=true,echo=true>>=
a<-1
2+a
a=1
2+a
a=2+2
a/4
@
\end{frame}
%%%%%%
\begin{frame}[t,fragile]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.01in} basics}
Assigning data to R objects is critical for analysis\\~\\
More complex assignments are possible\\~\\
<<eval=true,echo=true>>=
a<-c(1,2,3,4)
a
a<-seq(1,4)
a
a<-c("a","b","c")
a
@
\end{frame}
%%%%%%
\begin{frame}[fragile]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.01in} basics}
Anatomy of a function - functions perform tasks for you, much like in Excel
\begin{center}
\Large
function(arguments)
\end{center}
\onslide<2>
<<eval=true,echo=true>>=
c(1,2) #concatenate function
mean(c(1,2)) #mean function
seq(1,4) #create a sequence of values
@
\end{frame}
%%%%%%
\begin{frame}[fragile,t]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.01in} basics}
Understanding classes of R \href{http://cran.r-project.org/doc/manuals/r-release/R-lang.html#Vector-objects}{objects} is necessary for analysis \\~\\
An object is any variable of interest that you want to work with\\~\\
The class defines the type of information the object contains\\~\\
\onslide<2>
Most common are `numeric' or `character' classes \\~\\
<<echo=true,eval=true>>=
class(1)
class("1")
@
\vspace{0.2in}
\pause
`Factors' are also common, define categorical variables
\end{frame}
%%%%%%
\begin{frame}[fragile,t]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.01in} basics}
Understanding classes of R \href{http://cran.r-project.org/doc/manuals/r-release/R-lang.html#Vector-objects}{objects} is necessary for analysis \\~\\
The classes of an object defines a protocol for evaluating or organizing variables\\~\\
For example, we cannot add add two objects with different classes:\\~\\
<<echo=true,eval=false>>=
'1' + 1
@
\begin{Schunk}
\begin{Soutput}
Error in "1" + 1 : non-numeric argument to binary operator
\end{Soutput}
\end{Schunk}
\end{frame}
%%%%%%
\begin{frame}[fragile]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.01in} basics}
Objects (and their classes) can be stored in the computer's memory in different ways - aka the workspace for your R session\\~\\
Most common structures are `vectors' and `data.frames'\\~\\
\onslide<2->
Vectors are a collection of objects of the same class (e.g., a column in a table), whereas a data frame is analogous to a table with rows and columns (e.g., collection of vectors)
\onslide<3->
\begin{columns}[t]
\begin{column}{0.45\textwidth}
<<echo=true,eval=true>>=
a<-c(1,2)
a
b<-c("a","b")
b
@
\end{column}
\onslide<4->
\begin{column}{0.45\textwidth}
<<>>=
c<-data.frame(a,b)
c
@
\end{column}
\end{columns}
\end{frame}
%%%%%%
\begin{frame}[t,fragile]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.01in} basics}
How are data imported into R?\\~\\
R needs to know where the data are located on your computer:\\~\\
<<echo=true,results=tex,eval=false>>=
setwd("C:/projects/my_data/")
@
\vspace{0.2in}
This establishes a `working directory' for data import/export\\~\\
\onslide<2>
R can import almost any type of data but `spreadsheet' or text-based files are most common \\~\\
\end{frame}
%%%%%%
\begin{frame}[t,fragile]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.01in} basics}
How are data imported into R?\\~\\
R can import Excel data using the RODBC package, but this is not simple\\~\\
\onslide<2>
The easiest approach is to format data in Excel then export to a .csv or .txt file
\begin{columns}
\begin{column}{0.43\textwidth}
\begin{center}
\includegraphics{my_dat.png}
\end{center}
\end{column}
\begin{column}{0.66\textwidth}
\begin{center}
\includegraphics{save_as.png}
\end{center}
\end{column}
\end{columns}
\end{frame}
%%%%%%
\begin{frame}[t,fragile]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.01in} basics}
How are data imported into R?\\~\\
Use the read.table or read.csv functions to import the data, must be in your working directory\\~\\
\onslide<2>
<<echo=true,eval=true>>=
dat<-read.csv("my_data.csv",header=T)
dat
@
\end{frame}
%%%%%%
\begin{frame}[t,fragile]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.01in} basics}
How are data imported into R?\\~\\
Use the read.table or read.csv functions to import the data, must be in your working directory\\~\\
<<echo=true,eval=true>>=
dat<-read.table("my_data.csv",sep=',',header=T)
dat
@
\end{frame}
%%%%%%
\begin{frame}[t,fragile]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.01in} basics}
Imported data can be viewed several ways, view the whole object or parts \\~\\
Rows or columns can be obtained by indexing with brackets separated by a comma: data[row,column]
\begin{columns}[t]
\onslide<2->
\begin{column}{0.45\textwidth}
<<echo=true>>=
dat
@
\end{column}
\onslide<3>
\begin{column}{0.45\textwidth}
<<>>=
dat[1,] #row 1
dat[,2] #column 2
dat[4,1] #row 4, column 1
@
\end{column}
\end{columns}
\end{frame}
%%%%%%
\begin{frame}[t,fragile]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.01in} basics}
Imported data can be viewed several ways, view the whole object or parts \\~\\
Access using column names or the attach function
\begin{columns}[t]
\begin{column}{0.49\textwidth}
<<echo=true>>=
dat$Value
dat[,'Value']
@
\end{column}
\begin{column}{0.49\textwidth}
<<>>=
attach(dat)
Value
@
\end{column}
\end{columns}
\vspace{0.3in}
\onslide<2>
Vectors can be indexed similarly as data frames\\~\\
<<>>=
Value[2]
@
\end{frame}
%%%%%%
\begin{frame}[t,fragile]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.01in} basics}
Where to go for help?\\~\\
\begin{itemize}
\addtolength{\itemsep}{0.08in}
\item A user-friendly \href{http://www.statmethods.net/}{intro to R} \pause
\item Several good introductory texts are available - Zuur et al. 2009. A Beginner's Guide to R. Springer. \pause
\item \href{http://cran.r-project.org/doc/contrib/Short-refcard.pdf}{R cheatsheet} \pause
\item Google is your friend \pause
\item Help files for each function using `?function' - may or may not be helpful \pause
\item An \href{http://cran.r-project.org/doc/manuals/R-intro.html}{intro to R} - very detailed
\item Ask us!
\end{itemize}
\end{frame}
% \begin{frame}[shrink]{References}%[t,allowframebreaks]{References}
% \scriptsize
% \setbeamertemplate{bibliography item}{}
% \bibliographystyle{C:/Projects/LaTeX/bibtex_bst/apalike_mine}
% \bibliography{C:/Projects/LaTeX/ref_diss}
% \end{frame}
\end{document}

\documentclass[xcolor=svgnames]{beamer}
\usetheme{Boadilla}
\usecolortheme[named=ForestGreen]{structure}
\usepackage{graphicx}
\usepackage[final]{animate}
%\usepackage[colorlinks=true,urlcolor=blue,citecolor=blue,linkcolor=blue]{hyperref}
\usepackage{breqn}
\usepackage{xcolor}
\usepackage{booktabs}
\usepackage{tikz}
\usetikzlibrary{shadows,arrows,positioning}
\usepackage[noae]{Sweave}
\definecolor{links}{HTML}{2A1B81}
\hypersetup{colorlinks,linkcolor=links,urlcolor=links}
\usepackage{pgfpages}
%\pgfpagesuselayout{4 on 1}[letterpaper, border shrink = 5mm, landscape]
\tikzstyle{block} = [rectangle, draw, text width=7em, text centered, rounded corners, minimum height=3em, minimum width=7em, top color = white, bottom color=green!30, drop shadow]
\begin{document}
\SweaveOpts{concordance=TRUE}
\title[R for Data Analysis]{\includegraphics[width=0.07\textwidth]{Rlogo.jpg} \hspace{0.2em} for Data Analysis}
\author[M. Beck and S. Berg]{Marcus W. Beck \and Sergey Berg}
\institute[UofM]{Department of Fisheries, Wildlife, and Conservation Biology \\ University of Minnesota, Twin Cities}
\date{May 21, 2013}
\titlegraphic{
\centerline{
\begin{tikzpicture}
\node[fill=white,draw] at (0,0) {\includegraphics[width=0.6\textwidth]{peeper.jpg}};
\end{tikzpicture}}
}
%%%%%%
\begin{frame}
\vspace{-0.3in}
\titlepage
\end{frame}
\section{Background}
%%%%%%
\begin{frame}{What you'll learn about \hspace{0.2em}\includegraphics[width=0.07\textwidth]{Rlogo.jpg}}
\setbeamercovered{again covered={\opaqueness<1->{25}}}
\onslide<1->
\begin{itemize}
\itemsep20pt
\item Data organization
\item Data exploration and visualization
\begin{itemize}
\item Common functions
\item Graphing tools
\end{itemize}
\item Data analysis and hypothesis testing
\begin{itemize}
\item Common functions
\item Evaluation of output
\item Graphing tools \\~\\
\end{itemize}
\end{itemize}
\pause
\Large
\centerline{\emph{Interactive! Interrupt me!}}
\end{frame}
\section{Data organization}
%%%%%%
\begin{frame}[fragile]{Data organization}
We'll use the same dataset we used in Excel, replicating the analyses\\~\\
First we have to import the data into our R `workspace' \\~\\
\pause
The workspace is a group of R objects that are loaded for our current session \\~\\
Data are loaded into the workspace by importing (or making within R) and assigning them to a variable (object) with a name of our choosing\\~\\
We can see what's loaded in our workspace:\\~\\
\pause
<<echo=true>>=
a<-c(1,2)
ls()
@
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data organization}
\onslide<+->{Import the data following this workflow:}\\~\\
\begin{center}
\begin{tikzpicture}[node distance=2.5cm, auto, >=stealth]
\onslide<2->{
\node[block] (a) {1. Open data in Excel and clean};}
\onslide<3->{
\node[block] (b) [right of=a, node distance=4.2cm] {2. Save data in `.csv' format};
\draw[->] (a) -- (b);}
\onslide<4->{
\node[block] (c) [right of=b, node distance=4.2cm] {3. Import in R using 'read.csv'};
\draw[->] (b) -- (c);}
\end{tikzpicture}
\end{center}
\begin{columns}[t]
\onslide<2->{
\begin{column}{0.33\textwidth}
\begin{itemize}
\item Column names should be simple
\item Ensure all data will be easy to read
\end{itemize}
\end{column}}
\onslide<3->{
\begin{column}{0.33\textwidth}
\begin{itemize}
\item File, Save as .csv
\item Creates a comma separated file that looks like a spreadsheet
\item One spreadsheet at a time
\end{itemize}
\end{column}}
\onslide<4->{
\begin{column}{0.33\textwidth}
\begin{itemize}
\item header = T
\item See ?read.csv for list of function options
\item Remember to assign a name
\end{itemize}
\end{column}}
\end{columns}
\end{frame}
%%%%%%
\begin{frame}[fragile,shrink]{Data organization}
If the data are a text file... open the text file, how are the columns separated?
\begin{itemize}
\item comma
\item tabs
\item space
\item arbitrary character\\~\\
\end{itemize}
\pause
Use the read.table function and identify the column delimiter:
<<echo=true>>=
setwd('C:/Documents/monitoring_workshop')
ls()
dat<-read.table('RWBB Survey.txt',sep='\t',header=T)
ls()
@
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data organization}
Now that the data are in our workspace, let's explore!\\~\\
\pause
Did the data import correctly (rarely a problem)?\\~\\
<<echo=true,eval=false>>=
head(dat) #or tail(dat)
@
\scriptsize
<<echo=false>>=
head(dat) #or tail(dat)
@
\end{frame}
\section{Data exploration}
%%%%%%
\begin{frame}[fragile]{Data exploration}
What object class is the data?
<<>>=
class(dat)
@
\pause
What are the dimensions of the data frame?
<<>>=
dim(dat)
nrow(dat)
ncol(dat)
@
The data contain \Sexpr{nrow(dat)} rows and \Sexpr{ncol(dat)} columns, is this correct?
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data exploration}
Can we get a summary of the data frame?
\pause
<<>>=
summary(dat)
@
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data exploration}
Individual summmaries of variables are also possible\\~\\
How do we obtain variables of interest?
\small
<<>>=
names(dat)
@
\pause
\normalsize
We can get a variable directly using \$ or via indexing with [,]
\small
<<>>=
dat$Temperature
dat[,'Temperature'] #same as dat[,7]
@
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data exploration}
Just as we had summaries of the data frame, we can get summaries of individual variables
<<>>=
summary(dat$Temperature)
@
\pause
Or more simplistically...
<<>>=
mean(dat$Temperature)
range(dat$Temperature)
unique(dat$Temperature)
@
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data exploration}
Note that the classes of our variables affect how R functions interpet them\\~\\
For example, the summary function returns different information...\\~\\
\small
<<>>=
class(dat$Temperature)
summary(dat$Temperature)
class(dat$SiteName)
summary(dat$SiteName)
@
\end{frame}
%%%%%%
\begin{frame}[fragile,t]{Data exploration}
What about site-specific evaluations? What if we want to look at the temperature only at Kelly?\\~\\
<<>>=
Kelly<-subset(dat, dat$SiteName=='Kelly')
@
\vspace{0.2in}
We've created a new object in our workspace that is our original data frame with sites only from Kelly\\~\\
\pause
<<>>=
dim(Kelly)
Kelly$SiteName
@
\end{frame}
%%%%%%
\begin{frame}[fragile,t]{Data exploration}
What about site-specific evaluations? What if we want to look at the temperature only at Kelly?\\~\\
<<>>=
Kelly<-subset(dat, dat$SiteName=='Kelly')
@
\vspace{0.2in}
Now we can evaluate the temperature, for example, only at Kelly\\~\\
<<>>=
mean(Kelly$Temperature) #this is the same as all sites
@
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data exploration}
What abour our restoration project? Aren't we comparing the abundances of breeding birds between restored and reference sites? \\~\\
Let's start with our reference sites...
<<>>=
ref<-dat$Reference
summary(ref) #or summary(dat$Reference)
@
\pause
Now the restored sites...
<<>>=
rest<-dat$Restoration
summary(rest)
@
\end{frame}
\section{Data visualization}
%%%%%%
\begin{frame}[fragile]{Data visualization}
Textual summaries of our data are nice, but we should also visualize:
\begin{itemize}
\item How are our data distributed?
\item Are there any outliers or extreme observations?
\item How do our variables compare (to a reference, to one another, over time, etc.)?\\~\\
\end{itemize}
\pause
R has many built in functions for data exploration and plotting
\begin{itemize}
\item hist - plots a histogram (binned densities of continuous values)
\item qqplot - comparison of a variable to a normal distribution
\item barplot - for bar plots...
\item plot - bivariate comparison of two variables
\item Much, much more...
\end{itemize}
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data visualization}
Let's examine the distribution of abundances for the breeding birds at our reference site\\~\\
\begin{columns}
\begin{column}{0.6\textwidth}
<<hist_ref,fig=true,width=6,height=5,include=false>>=
hist(ref) #or hist(dat$Reference)
@
\begin{center}
\includegraphics[width=\textwidth,trim=0in 0in 0.3in 0.3in]{R_for_data_analysis-hist_ref.pdf}
\end{center}
\end{column}
\begin{column}{0.4\textwidth}
\pause
14 of our reference sites have abundances between 0--5 breeding birds
\end{column}
\end{columns}
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data visualization}
How does it compare to our restoration site?\\~\\
\begin{columns}
\begin{column}{0.6\textwidth}
<<hist_rest,fig=true,width=6,height=5,include=false>>=
hist(rest) #or hist(dat$Restoration)
@
\begin{center}
\includegraphics[width=\textwidth,trim=0in 0in 0.3in 0.3in]{R_for_data_analysis-hist_rest.pdf}
\end{center}
\end{column}
\begin{column}{0.4\textwidth}
\pause
Six of our reference sites have abundances between 10--15 breeding birds
\end{column}
\end{columns}
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data visualization}
Now that we've seen the distribution, how can we compare directly?\\~\\
<<box,fig=true,width=6,height=5,include=false>>=
boxplot(ref,rest)
@
\begin{columns}
\begin{column}{0.6\textwidth}
\begin{center}
\includegraphics[width=\textwidth,trim=0in 0in 0.3in 0.3in]{R_for_data_analysis-box.pdf}
\end{center}
\end{column}
\begin{column}{0.4\textwidth}
\pause
Let's make it look better...
\end{column}
\end{columns}
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data visualization}
Now that we've seen the distribution, how can we compare directly?\\~\\
<<box2,fig=true,width=6,height=5,include=false>>=
boxplot(ref,rest,names=c('Reference','Restoration'),
ylab='Bird abundance',col=c('lightblue','lightgreen'),
main='Comparison of abundances between sites')
@
\begin{columns}
\begin{column}{0.6\textwidth}
\pause
\begin{center}
\includegraphics[width=\textwidth,trim=0in 0in 0.3in 0.3in]{R_for_data_analysis-box2.pdf}
\end{center}
\end{column}
\begin{column}{0.4\textwidth}
\pause
Dark line is median, box is 25$^{th}$ to 75$^{th}$ quartile (or IQR), whiskers are 1.5 $\times$ IQR\\~\\
Beyond can be considered outliers...
\end{column}
\end{columns}
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data visualization}
What's going on with the outlier at our reference site? How can we identify it? \\~\\
We can use the boxplot function for the dirty work...\\~\\
\pause
<<>>=
myplot<-boxplot(ref,rest)
myplot$out
@
\vspace{0.2in}
This gives us the actual value, now we need to find it in our data frame \\~\\
\pause
<<>>=
outlier<-myplot$out
out.row<-which(ref==outlier)
out.row #this is the row number
@
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data visualization}
<<eval=false>>=
dat[out.row,] #same as dat[8,]
@
\scriptsize
<<echo=false>>=
dat[out.row,] #same as dat[8,]
@
\vspace{0.2in}
\normalsize
Now we know that our outlier was from Kelly in 2007...\\~\\
What's odd about this record? \\~\\
\pause
Let's look at our records from Kelly...\\~\\
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data visualization}
<<eval=false>>=
Kelly
@
\scriptsize
<<echo=false>>=
Kelly
@
\normalsize
\vspace{0.2in}
\pause
2007 was cold and rainy, could that have been the reason?\\~\\
Let's look at 2007 for all sites...
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data visualization}
<<eval=false>>=
subset(dat,dat$Year=='2007')
@
\pause
\scriptsize
<<echo=false>>=
subset(dat,dat$Year=='2007')
@
\normalsize
\vspace{0.2in}
\pause
IGH and Carlton don't have high abundances at their reference sites during 2007 even though the weather was the same \\~\\
What else could have caused this outlier?\\~\\
\pause
<<eval=false>>=
summary(dat$ObserverNames)
@
\pause
\scriptsize
<<echo=false>>=
summary(dat$ObserverNames)
@
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data visualization}
<<eval=false>>=
summary(dat$ObserverNames)
@
\scriptsize
<<echo=false>>=
summary(dat$ObserverNames)
@
\normalsize
\vspace{0.2in}
This is probably Jeremy and/or Lucy's fault, most likely switched the restoration and reference records \\~\\
\pause
What to change?
\pause
<<eval=false>>=
dat[out.row,'Restoration']<-18
dat[out.row,'Reference']<-2
@
Or...
<<eval=true>>=
dat<-dat[-out.row,] #do this one
@
Or...
fire Jeremy and Lucy.
\end{frame}
\section{Data analysis and hypothesis testing}
%%%%%%
\begin{frame}{Data analysis and hypothesis testing}
Now we need to evaluate the statistical certainty of our data, i.e., are our results due to random chance and how can we quantify this?\\~\\
\begin{columns}
\begin{column}{0.5\textwidth}
\begin{center}
\includegraphics[width=\textwidth,trim=0in 0in 0.3in 0.3in]{R_for_data_analysis-box2.pdf}
\end{center}
\end{column}
\begin{column}{0.5\textwidth}
\pause
We want to determine if the abundance of birds or variation among sites is actual or random\\~\\
\end{column}
\end{columns}
\pause
\centerline{What is an appropriate hypothesis?}
\end{frame}
<<hyp1,fig=T,include=false,eval=true,width=3.5,height=4.5,echo=false>>=
boxplot(dat$Reference,col='lightblue',main='Boxplot of abundance\nat reference sites',ylab='Bird abundance',ylim=c(-1,8))
abline(h=0,lty=2,lwd=2)
@
%%%%%%
\begin{frame}{Data analysis and hypothesis testing}
\centerline{What is an appropriate hypothesis? Let's start simple...}
\vspace{0.2in}
\pause
\begin{columns}
\begin{column}{0.5\textwidth}
\begin{block}{Null hypothesis}
The mean abundance of breeding birds at our reference site is zero.
\end{block}
\pause
\vspace{0.2in}
\begin{block}{Alternative hypothesis}
The mean abundance of breeding birds at our reference site is not zero.
\end{block}
\end{column}
\begin{column}{0.5\textwidth}
\pause
\centerline{\includegraphics[width=0.85\textwidth,trim=0in 0.8in 0in 0in]{R_for_data_analysis-hyp1.pdf}}
\end{column}
\end{columns}
\end{frame}
%%%%%%
\begin{frame}[t,fragile]{Data analysis and hypothesis testing}
The t.test function lets us test this hypothesis, very simple...\\~\\
<<eval=false>>=
t.test(dat$Reference)
@
\pause
\small
<<echo=false>>=
t.test(dat$Reference)
@
\normalsize
\vspace{0.2in}
\pause
What does this mean? \pause What are default arguments?\\~\\
\end{frame}
%%%%%%
\begin{frame}[t]{Data analysis and hypothesis testing}
Perhaps a one-tailed alternative hypothesis is better, we have prior assumptions about the data...\\~\\
\pause
\begin{columns}
\begin{column}{0.5\textwidth}
\begin{block}{Null hypothesis}
The mean abundance of breeding birds at our reference site is zero.
\end{block}
\pause
\vspace{0.2in}
\begin{block}{Alternative hypothesis}
The mean abundance of breeding birds at our reference site is greater than zero.
\end{block}
\end{column}
\begin{column}{0.5\textwidth}
\pause
\centerline{\includegraphics[width=0.85\textwidth,trim=0in 0.8in 0in 0in]{R_for_data_analysis-hyp1.pdf}}
\end{column}
\end{columns}
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data analysis and hypothesis testing}
Slight modification of alternative argument for one-tailed test, default is two-tailed\\~\\
<<eval=false>>=
t.test(dat$Reference, alternative='greater')
@
\pause
\small
<<echo=false>>=
t.test(dat$Reference, alternative='greater')
@
\normalsize
\pause
What does this mean?
\end{frame}
<<hyp2,fig=T,include=false,eval=true,width=3.5,height=4.5,echo=false>>=
boxplot(dat$Reference,col='lightblue',main='Boxplot of abundance\nat reference sites',ylab='Bird abundance',ylim=c(-1,8))
abline(h=4,lty=2,lwd=2)
@
%%%%%%
\begin{frame}[t]{Data analysis and hypothesis testing}
Let's explore more flexibility of the t.test function by changing our basis of comparison for the alternative hypothesis\\~\\
\pause
\begin{columns}
\begin{column}{0.5\textwidth}
\begin{block}{Null hypothesis}
The mean abundance of breeding birds at our reference site is four.
\end{block}
\pause
\vspace{0.2in}
\begin{block}{Alternative hypothesis}
The mean abundance of breeding birds at our reference site is greater than four.
\end{block}
\end{column}
\begin{column}{0.5\textwidth}
\pause
\centerline{\includegraphics[width=0.85\textwidth,trim=0in 0.8in 0in 0in]{R_for_data_analysis-hyp2.pdf}}
\end{column}
\end{columns}
\end{frame}
%%%%%%
\begin{frame}[fragile,t]{Data analysis and hypothesis testing}
Test a different alternative hypothesis by changing the mu argument\\~\\
<<eval=false>>=
t.test(dat$Reference, mu=4, alternative='greater')
@
\pause
\small
<<echo=false>>=
t.test(dat$Reference, mu=4, alternative='greater')
@
\pause
\normalsize
What does this mean?
\end{frame}
%%%%%%
\begin{frame}{Data analysis and hypothesis testing}
Now the real question, let's compare our sites to one another...\\~\\
What are our hypotheses?\\~\\
\pause
\begin{columns}
\begin{column}{0.5\textwidth}
\begin{block}{Null hypothesis}
Differences in the mean abundance between restoration and reference sites is zero.
\end{block}
\pause
\vspace{0.2in}
\begin{block}{Alternative hypothesis}
Differences in the mean abundance between restoration and reference sites will be greater than zero.
\end{block}
\end{column}
\begin{column}{0.5\textwidth}
\pause
\centerline{\includegraphics[width=0.85\textwidth,trim=0in 1in 0.5in 0.5in]{R_for_data_analysis-box2.pdf}}
\end{column}
\end{columns}
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data analysis and hypothesis testing}
Use the t.test function again as a two-sample test, order matters as do arguments\\~\\
<<eval=false>>=
t.test(dat$Restoration,dat$Reference,
alternative='greater',var.equal=T)
@
\pause
\small
<<echo=false>>=
t.test(dat$Restoration,dat$Reference,
alternative='greater',var.equal=T)
@
\normalsize
\pause
What does this mean?
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data analysis and hypothesis testing}
Order of arguments matters...\\~\\
<<eval=false>>=
t.test(dat$Reference,dat$Restoration,
alternative='greater',var.equal=T)
@
\pause
\small
<<echo=false>>=
t.test(dat$Reference,dat$Restoration,
alternative='greater',var.equal=T)
@
\normalsize
\pause
What does this mean? \pause What happens if we change the alternative argument?
\end{frame}
%%%%%
\begin{frame}{Data analysis and hypothesis testing}
Our results suggest that the abundance of breeding birds at the restoration site is significantly greater than at the reference site
\pause
\vspace{0.5in}
\begin{columns}
\begin{column}{0.5\textwidth}
\centerline{\includegraphics[width=0.85\textwidth,trim=0in 1in 0.5in 0.5in]{R_for_data_analysis-box2.pdf}}
\end{column}
\begin{column}{0.5\textwidth}
Our p-value is 4.006e-06, what does this mean?\\~\\
\pause
There is a 0.0004006\% chance that our results were observed due to randomness (within the constraints of our test).
\end{column}
\end{columns}
\end{frame}
%%%%%%
\begin{frame}[t]{Data analysis and hypothesis testing}
Other common tests:\\~\\
\begin{itemize}
\itemsep20pt
\item $\chi^2$ test of independence - chisq.test
\item analysis of variance - anova or aov
\item correlations - cor.test or cor
\item regression - lm or glm
\item Much, much more....
\end{itemize}
\end{frame}
%%%%%
\begin{frame}{Data analysis and hypothesis testing}
One last example... we've used common tests to compare our data to a standard or reference (e.g., mean is zero, differences in means is greater than zero)\\~\\
What about a more interesting analysis, such as comparison of data over time or relationships between variables?\\~\\
We'll close by illustrating use of linear regression with our data\\~\\
This is an evaluation of the mean response of a variable conditional on another, i.e., a predictor
\end{frame}
<<reg1,fig=true,include=false,eval=true,echo=false,width=4,height=4>>=
par(mar=c(4,4,0.5,0.5))
plot(Restoration~Year,data=dat)
@
%%%%%%
\begin{frame}[fragile]{Data analysis and hypothesis testing}
Perhaps we expect the abundance of breeding birds to increase at our restoration site over time, let's plot it:\\~\\
<<eval=false>>=
plot(Restoration~Year,data=dat)
@
\vspace{-0.13in}
\pause
\begin{columns}
\begin{column}{0.5\textwidth}
The first argument is entered as a `formula' specifying the variables\\~\\
The data argument specifies location of the variables in the workspace
\end{column}
\begin{column}{0.5\textwidth}
\begin{center}
\includegraphics[width=0.9\textwidth]{R_for_data_analysis-reg1.pdf}
\end{center}
\end{column}
\end{columns}
\end{frame}
<<reg2,fig=true,include=false,eval=true,echo=false,width=4,height=4>>=
par(mar=c(4,4,0.5,0.5))
plot(dat$Year,dat$Restoration)
@
%%%%%%
\begin{frame}[fragile]{Data analysis and hypothesis testing}
We can also call the variables directly in the plot function, x variable first, y second:\\~\\
<<eval=false>>=
plot(dat$Year,dat$Restoration)
@
\vspace{-0.13in}
\begin{columns}
\begin{column}{0.5\textwidth}
\onslide<2->
Note the change of the x and y labels, we can modify these using the xlab and ylab arguments in the plot function\\~\\
\onslide<3->
Notice the clear trend...
\end{column}
\begin{column}{0.5\textwidth}
\onslide<2->
\begin{center}
\includegraphics[width=0.9\textwidth]{R_for_data_analysis-reg2.pdf}
\end{center}
\end{column}
\end{columns}
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data analysis and hypothesis testing}
How do we quantify this trend across time? Use the lm function for regression...\\~\\
<<eval=false>>=
lm(Restoration~Year,data=dat)
@
\pause
<<echo=false>>=
lm(Restoration~Year,data=dat)
@
\vspace{0.2in}
\pause
The abundance increases, on average, by \Sexpr{round(lm(Restoration~Year,data=dat)$coefficients[2],3)} birds per year.
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data analysis and hypothesis testing}
We can get more information using the summary command
\vspace{0.1in}
<<eval=false>>=
mod<-lm(Restoration~Year,data=dat)
summary(mod)
@
\pause
\scriptsize
<<echo=false>>=
mod<-lm(Restoration~Year,data=dat)
summary(mod)
@
\end{frame}
%%%%%%
\begin{frame}[fragile]{Data analysis and hypothesis testing}
What does this mean?
\vspace{0.1in}
\scriptsize
<<echo=false>>=
mod<-lm(Restoration~Year,data=dat)
summary(mod)
@
\end{frame}
<<reg3,fig=true,include=false,eval=true,echo=false,width=4,height=4>>=
par(mar=c(4,4,0.5,0.5))
plot(Restoration~Year, data=dat)
abline(reg=mod)
@
%%%%%%
\begin{frame}[fragile]{Data analysis and hypothesis testing}
How do we plot the model?\\~\\
<<eval=false>>=
plot(Restoration~Year, data=dat)
abline(reg=mod)
@
\vspace{-0.3in}
\begin{columns}
\begin{column}{0.5\textwidth}
We tell the abline function to plot our model, named `mod'
\end{column}
\begin{column}{0.5\textwidth}
\pause
\begin{center}
\includegraphics[width=0.9\textwidth]{R_for_data_analysis-reg3.pdf}
\end{center}
\end{column}
\end{columns}
\end{frame}
%%%%%
\begin{frame}[fragile]{Data analysis and hypothesis testing}
Can we use our model for prediction?\\~\\
What are the predicted data for our observation years?\\~\\
<<eval=false>>=
predict(mod)
@
\scriptsize
\pause
<<echo=false>>=
predict(mod)
@
\vspace{0.2in}
\normalsize
\pause
What about other years not in our dataset?
\end{frame}
%%%%%
\begin{frame}[fragile]{Data analysis and hypothesis testing}
Can we use our model for prediction?\\~\\
What about predicted abundance for 2011?\\~\\
<<eval=false>>=
predict(mod,newdata=data.frame(Year=2011))
@
\pause
<<echo=false>>=
predict(mod,newdata=data.frame(Year=2011))
@
\vspace{0.2in}
We can expect, on average, \Sexpr{round(predict(mod,newdata=data.frame(Year=2011)),2)} birds at our restoration sites in 2011 (within the constraints of our model)
\end{frame}
\section{Conclusion}
%%%%%
\begin{frame}{Conclusion}
What we've learned:\\~\\
\begin{itemize}
\itemsep20pt
\item Data organization - read.csv, read.table
\item Data exploration - head, dim, nrow, ncol, summary, [,], \$, names, subset, mean, range, unique
\item Data visualization - hist, boxplot, plot, abline
\item Data analysis and hypothesis testing - t.test, lm, predict\\~\\
\end{itemize}
\LARGE
\centerline{\emph{Questions?}}
\end{frame}
\end{document}

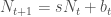

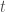




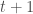


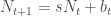

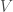









 specific and slightly biased towards Windows OS, so it probably has limited relevance if you are interested in other methods. Anyhow, I hope this is useful to some of you.
specific and slightly biased towards Windows OS, so it probably has limited relevance if you are interested in other methods. Anyhow, I hope this is useful to some of you. 


















































{kind=link}
{kind=link}
{kind=link}